
CFD Performance Comparison Between GPU and CPU
For the GPU Technology Conference 2013 (GTC13) I performed a series of simulations in Caedium comparing the OpenFOAM® linear solver GPU option using ofgpu with the standard CPU shared memory option using MPI. See selected slides and the presentation deck below.

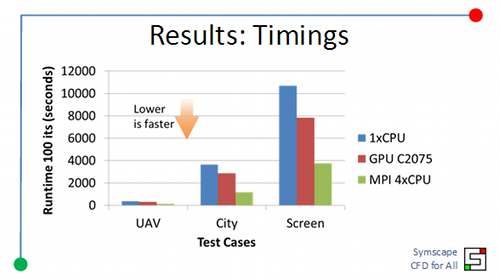
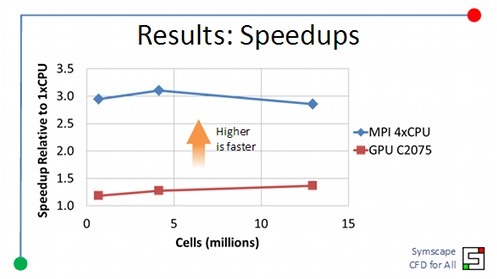
Clearly there is still more work to do to make the GPU accelerated linear solvers competitive with the highly optimized MPI compatibility in OpenFOAM. The good news is that the NVIDIA CUDA software continues to improve with each new release and the GPU hardware performance is increasing faster than Moore's Law.
OpenFOAM is a registered trademark of OpenCFD and is unaffiliated with Symscape.
Feedback
Questions? Ideas? Problems?

Recent blog posts
- CFD Simulates Distant Past
- Background on the Caedium v6.0 Release
- Long-Necked Dinosaurs Succumb To CFD
- CFD Provides Insight Into Mystery Fossils
- Wind Turbine Design According to Insects
- Runners Discover Drafting
- Wind Tunnel and CFD Reveal Best Cycling Tuck
- Active Aerodynamics on the Lamborghini Huracán Performante
- Fluidic Logic
- Stonehenge Vortex Revealed as April Fools' Day Distortion Field
 Get our Blog feed
Get our Blog feed
Comments
OpenFOAM on GPU vs CPU
Hi,
I am just wondering that why a GPU code with slower than CPU. On its face, it seems that GPU has more no. of cores and sufficient memory (6 GB) to run a simulation of 4 M cells. Could you just tell the reason why it is slower?
Thanks
Vivek
GPU vs CPU preformance
There are four major things to keep in mind when talking about comparing multi-core processing performance: Overhead, memory, Instructions Per Clock(IPC) and clock speed.
While memory is limited more on the GPU, as you've pointed out this is not an issue right now.
For any particular workload each core can operate a certain number of operations (addition, multiplication, etc) per clock cycle. This is the first place where CPUs typically have an advantage, as per clock cycle CPUs process more operations than GPUs.
Second, CPUs are clocked much higher than GPUs, CPUs typically on the order of 3-5Ghz while GPU's are on the order of 1-2Ghz.
Third is overhead, which is the amount of processing effort required to break up the workload over the available cores. Basically the more cores the more processing upfront it takes.
So if you've got a bunch of slower processor cores it can take more time to breakup the workload and then run it than breaking it up over a smaller number of faster cores.